Using Pretrained Models#
The first step is to load the training dataset, validation dataset, and test dataset. For an explanation, see the notebook Example: Classifying Images - Dogs vs. Cats
from tensorflow.keras.utils import image_dataset_from_directory
import os
import shutil
import pathlib
original_dir = pathlib.Path("dogs-vs-cats/train")
new_base_dir = pathlib.Path("cats_vs_dogs_small")
train_dataset = image_dataset_from_directory( new_base_dir / "train", image_size=(180, 180), batch_size=32)
validation_dataset = image_dataset_from_directory( new_base_dir / "validation", image_size=(180, 180), batch_size=32)
test_dataset = image_dataset_from_directory( new_base_dir / "test", image_size=(180, 180), batch_size=32)
2025-05-08 15:04:18.053916: I external/local_xla/xla/tsl/cuda/cudart_stub.cc:32] Could not find cuda drivers on your machine, GPU will not be used.
2025-05-08 15:04:18.057067: I external/local_xla/xla/tsl/cuda/cudart_stub.cc:32] Could not find cuda drivers on your machine, GPU will not be used.
2025-05-08 15:04:18.065486: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:467] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
E0000 00:00:1746716658.079204 54026 cuda_dnn.cc:8579] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
E0000 00:00:1746716658.083307 54026 cuda_blas.cc:1407] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
W0000 00:00:1746716658.094572 54026 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1746716658.094582 54026 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1746716658.094584 54026 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1746716658.094586 54026 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
2025-05-08 15:04:18.098823: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
Found 0 files belonging to 1 classes.
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[1], line 8
5 original_dir = pathlib.Path("dogs-vs-cats/train")
6 new_base_dir = pathlib.Path("cats_vs_dogs_small")
----> 8 train_dataset = image_dataset_from_directory( new_base_dir / "train", image_size=(180, 180), batch_size=32)
10 validation_dataset = image_dataset_from_directory( new_base_dir / "validation", image_size=(180, 180), batch_size=32)
12 test_dataset = image_dataset_from_directory( new_base_dir / "test", image_size=(180, 180), batch_size=32)
File /opt/hostedtoolcache/Python/3.11.12/x64/lib/python3.11/site-packages/keras/src/utils/image_dataset_utils.py:329, in image_dataset_from_directory(directory, labels, label_mode, class_names, color_mode, batch_size, image_size, shuffle, seed, validation_split, subset, interpolation, follow_links, crop_to_aspect_ratio, pad_to_aspect_ratio, data_format, verbose)
325 image_paths, labels = dataset_utils.get_training_or_validation_split(
326 image_paths, labels, validation_split, subset
327 )
328 if not image_paths:
--> 329 raise ValueError(
330 f"No images found in directory {directory}. "
331 f"Allowed formats: {ALLOWLIST_FORMATS}"
332 )
334 dataset = paths_and_labels_to_dataset(
335 image_paths=image_paths,
336 image_size=image_size,
(...) 347 seed=seed,
348 )
350 if batch_size is not None:
ValueError: No images found in directory cats_vs_dogs_small/train. Allowed formats: ('.bmp', '.gif', '.jpeg', '.jpg', '.png')
Load a Pretrained Model#
We will use the VGG16 architecture, developed by Karen Simonyan and Andrew Zisserman in 2014. This is availabel in the keras.applications module. The model is trained on the ImageNet dataset, which contains 1.2 million images in 1000 classes. The model has 16 layers and is a convolutional neural network (CNN).
import keras
conv_base = keras.applications.vgg16.VGG16(
weights="imagenet",
include_top=False,
input_shape=(180, 180, 3))
conv_base.summary()
Model: "vgg16"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ input_layer_7 (InputLayer) │ (None, 180, 180, 3) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block1_conv1 (Conv2D) │ (None, 180, 180, 64) │ 1,792 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block1_conv2 (Conv2D) │ (None, 180, 180, 64) │ 36,928 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block1_pool (MaxPooling2D) │ (None, 90, 90, 64) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block2_conv1 (Conv2D) │ (None, 90, 90, 128) │ 73,856 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block2_conv2 (Conv2D) │ (None, 90, 90, 128) │ 147,584 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block2_pool (MaxPooling2D) │ (None, 45, 45, 128) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block3_conv1 (Conv2D) │ (None, 45, 45, 256) │ 295,168 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block3_conv2 (Conv2D) │ (None, 45, 45, 256) │ 590,080 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block3_conv3 (Conv2D) │ (None, 45, 45, 256) │ 590,080 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block3_pool (MaxPooling2D) │ (None, 22, 22, 256) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block4_conv1 (Conv2D) │ (None, 22, 22, 512) │ 1,180,160 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block4_conv2 (Conv2D) │ (None, 22, 22, 512) │ 2,359,808 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block4_conv3 (Conv2D) │ (None, 22, 22, 512) │ 2,359,808 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block4_pool (MaxPooling2D) │ (None, 11, 11, 512) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block5_conv1 (Conv2D) │ (None, 11, 11, 512) │ 2,359,808 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block5_conv2 (Conv2D) │ (None, 11, 11, 512) │ 2,359,808 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block5_conv3 (Conv2D) │ (None, 11, 11, 512) │ 2,359,808 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block5_pool (MaxPooling2D) │ (None, 5, 5, 512) │ 0 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 14,714,688 (56.13 MB)
Trainable params: 14,714,688 (56.13 MB)
Non-trainable params: 0 (0.00 B)
Extract Features from the Model#
import numpy as np
def get_features_and_labels(dataset):
all_features = []
all_labels = []
for images, labels in dataset:
preprocessed_images = keras.applications.vgg16.preprocess_input(images)
features = conv_base.predict(preprocessed_images)
all_features.append(features)
all_labels.append(labels)
return np.concatenate(all_features), np.concatenate(all_labels)
train_features, train_labels = get_features_and_labels(train_dataset)
val_features, val_labels = get_features_and_labels(validation_dataset)
test_features, test_labels = get_features_and_labels(test_dataset)
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 147ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 74ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 67ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 72ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 72ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 67ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 72ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 72ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 72ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 66ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 67ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 136ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
2025-04-14 21:32:18.392142: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 80ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 73ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 73ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 72ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 66ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 67ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 85ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 67ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
2025-04-14 21:32:21.528553: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 72ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 72ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 67ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 66ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 67ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 67ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 67ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 67ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 71ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 69ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 68ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 66ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 67ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 73ms/step
2025-04-14 21:32:27.588950: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence
The features of the training set are extracted using the VGG16 model and stored in train_featrues. The shape of the train_features is (2001, 5, 5, 512)
print(train_features.shape)
print(train_labels.shape)
(2001, 5, 5, 512)
(2001,)
Build a Model to Train on the Extracted Features#
from tensorflow.keras import layers
inputs = keras.Input(shape=(5, 5, 512))
x = layers.Flatten()(inputs)
x = layers.Dense(256)(x)
#x = layers.Dense(126)(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(loss="binary_crossentropy",
optimizer="rmsprop",
metrics=["accuracy"])
callbacks = [ keras.callbacks.ModelCheckpoint(
filepath="feature_extraction.keras",
save_best_only=True,
monitor="val_loss")
]
history = model.fit(
train_features,
train_labels,
epochs=20,
validation_data=(val_features, val_labels),
callbacks=callbacks)
Epoch 1/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 2s 19ms/step - accuracy: 0.8849 - loss: 21.1568 - val_accuracy: 0.9600 - val_loss: 5.3063
Epoch 2/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.9735 - loss: 3.6834 - val_accuracy: 0.9540 - val_loss: 9.7745
Epoch 3/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.9881 - loss: 1.1636 - val_accuracy: 0.9610 - val_loss: 7.4281
Epoch 4/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - accuracy: 0.9928 - loss: 1.0538 - val_accuracy: 0.9760 - val_loss: 4.7641
Epoch 5/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.9929 - loss: 1.2779 - val_accuracy: 0.9730 - val_loss: 4.6406
Epoch 6/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.9967 - loss: 0.7020 - val_accuracy: 0.9750 - val_loss: 4.2057
Epoch 7/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - accuracy: 0.9945 - loss: 0.4465 - val_accuracy: 0.9750 - val_loss: 5.1827
Epoch 8/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - accuracy: 0.9977 - loss: 0.3570 - val_accuracy: 0.9740 - val_loss: 5.6331
Epoch 9/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.9972 - loss: 0.4875 - val_accuracy: 0.9720 - val_loss: 5.7211
Epoch 10/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.9936 - loss: 0.4117 - val_accuracy: 0.9740 - val_loss: 5.3676
Epoch 11/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 14ms/step - accuracy: 0.9995 - loss: 0.0491 - val_accuracy: 0.9700 - val_loss: 8.0589
Epoch 12/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.9981 - loss: 0.3627 - val_accuracy: 0.9780 - val_loss: 4.9366
Epoch 13/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.9983 - loss: 0.0959 - val_accuracy: 0.9720 - val_loss: 6.9656
Epoch 14/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 15ms/step - accuracy: 0.9976 - loss: 0.1070 - val_accuracy: 0.9690 - val_loss: 7.1921
Epoch 15/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.9978 - loss: 0.0642 - val_accuracy: 0.9720 - val_loss: 5.7565
Epoch 16/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 1.0000 - loss: 0.0000e+00 - val_accuracy: 0.9720 - val_loss: 5.7565
Epoch 17/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - accuracy: 0.9993 - loss: 0.1761 - val_accuracy: 0.9740 - val_loss: 5.7473
Epoch 18/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.9983 - loss: 0.0795 - val_accuracy: 0.9720 - val_loss: 9.0802
Epoch 19/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 0.9983 - loss: 0.0524 - val_accuracy: 0.9710 - val_loss: 7.4118
Epoch 20/20
63/63 ━━━━━━━━━━━━━━━━━━━━ 1s 12ms/step - accuracy: 1.0000 - loss: 0.0000e+00 - val_accuracy: 0.9710 - val_loss: 7.4118
import matplotlib.pyplot as plt
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, "bo", label="Training accuracy")
plt.plot(epochs, val_acc, "b", label="Validation accuracy")
plt.title("Training and validation accuracy")
plt.legend()
plt.figure()
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.legend()
plt.show()
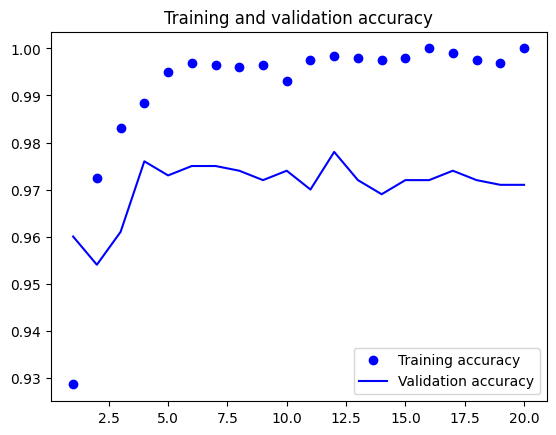
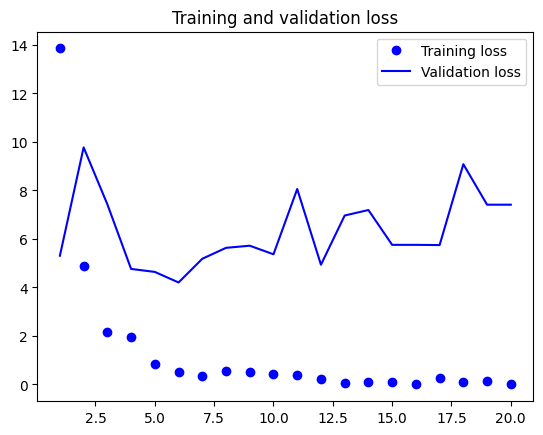
Feature Extraction with Data Augmentation#
conv_base = keras.applications.vgg16.VGG16(
weights="imagenet",
include_top=False)
conv_base.trainable = False
conv_base.summary()
Model: "vgg16"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ input_layer_9 (InputLayer) │ (None, None, None, 3) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block1_conv1 (Conv2D) │ (None, None, None, 64) │ 1,792 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block1_conv2 (Conv2D) │ (None, None, None, 64) │ 36,928 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block1_pool (MaxPooling2D) │ (None, None, None, 64) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block2_conv1 (Conv2D) │ (None, None, None, │ 73,856 │ │ │ 128) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block2_conv2 (Conv2D) │ (None, None, None, │ 147,584 │ │ │ 128) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block2_pool (MaxPooling2D) │ (None, None, None, │ 0 │ │ │ 128) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block3_conv1 (Conv2D) │ (None, None, None, │ 295,168 │ │ │ 256) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block3_conv2 (Conv2D) │ (None, None, None, │ 590,080 │ │ │ 256) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block3_conv3 (Conv2D) │ (None, None, None, │ 590,080 │ │ │ 256) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block3_pool (MaxPooling2D) │ (None, None, None, │ 0 │ │ │ 256) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block4_conv1 (Conv2D) │ (None, None, None, │ 1,180,160 │ │ │ 512) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block4_conv2 (Conv2D) │ (None, None, None, │ 2,359,808 │ │ │ 512) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block4_conv3 (Conv2D) │ (None, None, None, │ 2,359,808 │ │ │ 512) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block4_pool (MaxPooling2D) │ (None, None, None, │ 0 │ │ │ 512) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block5_conv1 (Conv2D) │ (None, None, None, │ 2,359,808 │ │ │ 512) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block5_conv2 (Conv2D) │ (None, None, None, │ 2,359,808 │ │ │ 512) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block5_conv3 (Conv2D) │ (None, None, None, │ 2,359,808 │ │ │ 512) │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block5_pool (MaxPooling2D) │ (None, None, None, │ 0 │ │ │ 512) │ │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 14,714,688 (56.13 MB)
Trainable params: 0 (0.00 B)
Non-trainable params: 14,714,688 (56.13 MB)
conv_base.trainable = True
print("This is the number of trainable weights " "before freezing the conv base:", len(conv_base.trainable_weights))
conv_base.trainable = False
print("This is the number of trainable weights " "after freezing the conv base:", len(conv_base.trainable_weights))
This is the number of trainable weights before freezing the conv base: 26
This is the number of trainable weights after freezing the conv base: 0
data_augmentation = keras.Sequential( [
layers.RandomFlip("horizontal"),
layers.RandomRotation(0.1),
layers.RandomZoom(0.2), ] )
inputs = keras.Input(shape=(180, 180, 3))
x = data_augmentation(inputs)
x = keras.applications.vgg16.preprocess_input(x)
x = conv_base(x)
x = layers.Flatten()(x)
x = layers.Dense(256)(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(loss="binary_crossentropy",
optimizer="rmsprop",
metrics=["accuracy"])
Warning
Training the above model will take a very long time if you are not using a GPU. If you are using a MAC, you need to install the following packages:
!pip install tensorflow-macos tensorflow-metal
import tensorflow as tf
print("Num GPUs Available:", len(tf.config.list_physical_devices('GPU')))
print("GPU Devices:", tf.config.list_physical_devices('GPU'))
print("Num CPUs Available:", len(tf.config.list_physical_devices('CPU')))
print("CPU Devices:", tf.config.list_physical_devices('CPU'))
Num GPUs Available: 1
GPU Devices: [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
Num CPUs Available: 1
CPU Devices: [PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU')]
callbacks = [ keras.callbacks.ModelCheckpoint(
filepath="feature_extraction_with_data_augmentation.keras",
save_best_only=True,
monitor="val_loss")
]
history = model.fit(
train_dataset,
epochs=50,
validation_data=validation_dataset,
callbacks=callbacks)
Epoch 1/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 133ms/step - accuracy: 0.8455 - loss: 40.0121 - val_accuracy: 0.9680 - val_loss: 4.6765
Epoch 2/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 8s 124ms/step - accuracy: 0.9441 - loss: 7.2953 - val_accuracy: 0.9730 - val_loss: 4.6430
Epoch 3/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 8s 121ms/step - accuracy: 0.9425 - loss: 6.0322 - val_accuracy: 0.9720 - val_loss: 4.2850
Epoch 4/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 7s 118ms/step - accuracy: 0.9544 - loss: 4.8687 - val_accuracy: 0.9620 - val_loss: 8.9179
Epoch 5/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 7s 118ms/step - accuracy: 0.9638 - loss: 3.7618 - val_accuracy: 0.9700 - val_loss: 5.1545
Epoch 6/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 8s 127ms/step - accuracy: 0.9563 - loss: 4.3614 - val_accuracy: 0.9780 - val_loss: 3.7368
Epoch 7/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 10s 157ms/step - accuracy: 0.9658 - loss: 4.1250 - val_accuracy: 0.9800 - val_loss: 2.7462
Epoch 8/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 8s 131ms/step - accuracy: 0.9694 - loss: 4.5216 - val_accuracy: 0.9720 - val_loss: 5.2145
Epoch 9/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 8s 128ms/step - accuracy: 0.9792 - loss: 2.2025 - val_accuracy: 0.9750 - val_loss: 4.0253
Epoch 10/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 10s 155ms/step - accuracy: 0.9724 - loss: 2.3472 - val_accuracy: 0.9830 - val_loss: 2.9074
Epoch 11/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 10s 161ms/step - accuracy: 0.9738 - loss: 2.2806 - val_accuracy: 0.9750 - val_loss: 4.5644
Epoch 12/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 147ms/step - accuracy: 0.9804 - loss: 1.2021 - val_accuracy: 0.9750 - val_loss: 3.3812
Epoch 13/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 147ms/step - accuracy: 0.9766 - loss: 1.6312 - val_accuracy: 0.9800 - val_loss: 2.6390
Epoch 14/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 10s 164ms/step - accuracy: 0.9795 - loss: 2.3468 - val_accuracy: 0.9780 - val_loss: 2.8700
Epoch 15/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 144ms/step - accuracy: 0.9846 - loss: 0.9025 - val_accuracy: 0.9770 - val_loss: 2.7988
Epoch 16/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 10s 159ms/step - accuracy: 0.9781 - loss: 1.5974 - val_accuracy: 0.9840 - val_loss: 2.3585
Epoch 17/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 138ms/step - accuracy: 0.9798 - loss: 1.6082 - val_accuracy: 0.9790 - val_loss: 2.6580
Epoch 18/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 146ms/step - accuracy: 0.9759 - loss: 2.1914 - val_accuracy: 0.9740 - val_loss: 2.7065
Epoch 19/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 10s 155ms/step - accuracy: 0.9847 - loss: 1.2099 - val_accuracy: 0.9740 - val_loss: 3.2106
Epoch 20/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 10s 162ms/step - accuracy: 0.9817 - loss: 1.3133 - val_accuracy: 0.9750 - val_loss: 2.9081
Epoch 21/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 11s 173ms/step - accuracy: 0.9793 - loss: 1.2852 - val_accuracy: 0.9790 - val_loss: 2.3218
Epoch 22/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 11s 176ms/step - accuracy: 0.9808 - loss: 1.2892 - val_accuracy: 0.9770 - val_loss: 3.2522
Epoch 23/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 12s 184ms/step - accuracy: 0.9804 - loss: 1.5253 - val_accuracy: 0.9710 - val_loss: 2.9104
Epoch 24/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 12s 191ms/step - accuracy: 0.9838 - loss: 0.8340 - val_accuracy: 0.9760 - val_loss: 2.4689
Epoch 25/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 13s 213ms/step - accuracy: 0.9825 - loss: 0.7155 - val_accuracy: 0.9830 - val_loss: 2.0190
Epoch 26/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 12s 196ms/step - accuracy: 0.9876 - loss: 0.6916 - val_accuracy: 0.9830 - val_loss: 2.0739
Epoch 27/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 12s 194ms/step - accuracy: 0.9874 - loss: 0.4766 - val_accuracy: 0.9770 - val_loss: 3.0073
Epoch 28/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 12s 190ms/step - accuracy: 0.9880 - loss: 0.7459 - val_accuracy: 0.9750 - val_loss: 2.7492
Epoch 29/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 12s 189ms/step - accuracy: 0.9824 - loss: 1.1594 - val_accuracy: 0.9770 - val_loss: 2.6248
Epoch 30/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 11s 181ms/step - accuracy: 0.9858 - loss: 1.0721 - val_accuracy: 0.9750 - val_loss: 2.6832
Epoch 31/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 11s 182ms/step - accuracy: 0.9870 - loss: 0.5940 - val_accuracy: 0.9740 - val_loss: 3.1164
Epoch 32/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 11s 179ms/step - accuracy: 0.9875 - loss: 0.6064 - val_accuracy: 0.9730 - val_loss: 2.4736
Epoch 33/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 11s 171ms/step - accuracy: 0.9834 - loss: 0.7716 - val_accuracy: 0.9800 - val_loss: 1.9184
Epoch 34/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 11s 177ms/step - accuracy: 0.9927 - loss: 0.2908 - val_accuracy: 0.9700 - val_loss: 3.6182
Epoch 35/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 11s 168ms/step - accuracy: 0.9864 - loss: 0.7105 - val_accuracy: 0.9750 - val_loss: 2.8357
Epoch 36/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 11s 167ms/step - accuracy: 0.9887 - loss: 0.4456 - val_accuracy: 0.9770 - val_loss: 2.0608
Epoch 37/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 10s 163ms/step - accuracy: 0.9855 - loss: 0.6110 - val_accuracy: 0.9780 - val_loss: 1.8177
Epoch 38/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 10s 158ms/step - accuracy: 0.9874 - loss: 0.6925 - val_accuracy: 0.9830 - val_loss: 1.6012
Epoch 39/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 10s 155ms/step - accuracy: 0.9798 - loss: 0.9790 - val_accuracy: 0.9810 - val_loss: 1.3883
Epoch 40/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 145ms/step - accuracy: 0.9886 - loss: 0.4643 - val_accuracy: 0.9830 - val_loss: 1.7916
Epoch 41/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 142ms/step - accuracy: 0.9867 - loss: 0.4009 - val_accuracy: 0.9810 - val_loss: 1.7673
Epoch 42/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 144ms/step - accuracy: 0.9889 - loss: 0.6490 - val_accuracy: 0.9790 - val_loss: 1.7854
Epoch 43/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 140ms/step - accuracy: 0.9859 - loss: 0.9514 - val_accuracy: 0.9800 - val_loss: 1.7813
Epoch 44/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 147ms/step - accuracy: 0.9879 - loss: 0.5197 - val_accuracy: 0.9770 - val_loss: 2.5787
Epoch 45/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 149ms/step - accuracy: 0.9826 - loss: 1.2753 - val_accuracy: 0.9800 - val_loss: 2.2108
Epoch 46/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 147ms/step - accuracy: 0.9913 - loss: 0.5583 - val_accuracy: 0.9700 - val_loss: 2.9584
Epoch 47/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 144ms/step - accuracy: 0.9906 - loss: 0.4762 - val_accuracy: 0.9800 - val_loss: 1.7853
Epoch 48/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 8s 135ms/step - accuracy: 0.9865 - loss: 0.7892 - val_accuracy: 0.9820 - val_loss: 1.7827
Epoch 49/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 135ms/step - accuracy: 0.9871 - loss: 0.4105 - val_accuracy: 0.9750 - val_loss: 2.2793
Epoch 50/50
63/63 ━━━━━━━━━━━━━━━━━━━━ 8s 134ms/step - accuracy: 0.9889 - loss: 0.5900 - val_accuracy: 0.9790 - val_loss: 1.8210
import matplotlib.pyplot as plt
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, "bo", label="Training accuracy")
plt.plot(epochs, val_acc, "b", label="Validation accuracy")
plt.title("Training and validation accuracy")
plt.legend()
plt.figure()
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.legend()
plt.show()
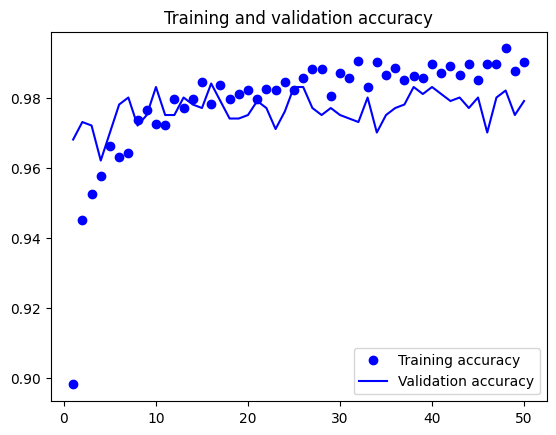
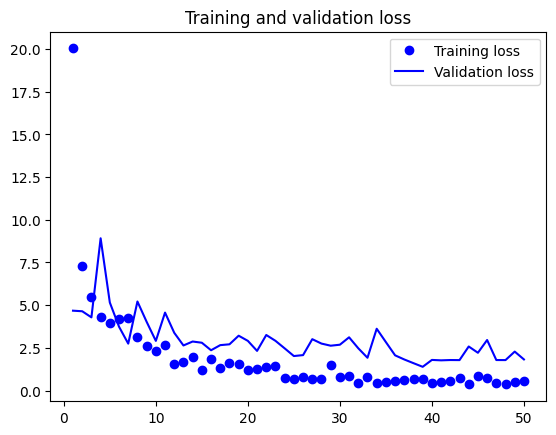
test_model = keras.models.load_model( "feature_extraction_with_data_augmentation.keras")
test_loss, test_acc = test_model.evaluate(test_dataset)
print(f"Test accuracy: {test_acc:.3f}")
63/63 ━━━━━━━━━━━━━━━━━━━━ 5s 66ms/step - accuracy: 0.9754 - loss: 1.9480
Test accuracy: 0.978
Fine-Tuning a Pretrained Model#
conv_base.trainable = True
for layer in conv_base.layers[:-4]:
layer.trainable = False
print("Number of trainable weights in the base conv " "model:", len(conv_base.trainable_weights))
print("Number of non-trainable weights in the base conv " "model:", len(conv_base.non_trainable_weights))
Number of trainable weights in the base conv model: 6
Number of non-trainable weights in the base conv model: 20
model.compile(loss="binary_crossentropy",
optimizer=keras.optimizers.RMSprop(learning_rate=1e-5),
metrics=["accuracy"])
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath="fine_tuning.keras",
save_best_only=True,
monitor="val_loss")
]
history = model.fit(
train_dataset,
epochs=30,
validation_data=validation_dataset,
callbacks=callbacks)
Epoch 1/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 11s 148ms/step - accuracy: 0.9894 - loss: 0.3535 - val_accuracy: 0.9800 - val_loss: 1.5894
Epoch 2/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 137ms/step - accuracy: 0.9948 - loss: 0.2454 - val_accuracy: 0.9790 - val_loss: 1.5223
Epoch 3/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 8s 132ms/step - accuracy: 0.9908 - loss: 0.2983 - val_accuracy: 0.9790 - val_loss: 1.5386
Epoch 4/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 8s 135ms/step - accuracy: 0.9912 - loss: 0.3468 - val_accuracy: 0.9760 - val_loss: 1.4670
Epoch 5/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 8s 130ms/step - accuracy: 0.9957 - loss: 0.2156 - val_accuracy: 0.9750 - val_loss: 1.5543
Epoch 6/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 8s 135ms/step - accuracy: 0.9930 - loss: 0.2811 - val_accuracy: 0.9810 - val_loss: 1.2739
Epoch 7/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 137ms/step - accuracy: 0.9885 - loss: 0.2284 - val_accuracy: 0.9780 - val_loss: 1.4460
Epoch 8/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 8s 133ms/step - accuracy: 0.9900 - loss: 0.2541 - val_accuracy: 0.9770 - val_loss: 2.1053
Epoch 9/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 136ms/step - accuracy: 0.9924 - loss: 0.2024 - val_accuracy: 0.9780 - val_loss: 1.7254
Epoch 10/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 141ms/step - accuracy: 0.9973 - loss: 0.0507 - val_accuracy: 0.9800 - val_loss: 1.5670
Epoch 11/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 137ms/step - accuracy: 0.9938 - loss: 0.1416 - val_accuracy: 0.9810 - val_loss: 1.5221
Epoch 12/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 8s 134ms/step - accuracy: 0.9957 - loss: 0.1131 - val_accuracy: 0.9780 - val_loss: 1.5936
Epoch 13/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 137ms/step - accuracy: 0.9964 - loss: 0.0402 - val_accuracy: 0.9810 - val_loss: 1.3712
Epoch 14/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 146ms/step - accuracy: 0.9947 - loss: 0.1655 - val_accuracy: 0.9810 - val_loss: 1.3156
Epoch 15/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 139ms/step - accuracy: 0.9965 - loss: 0.0385 - val_accuracy: 0.9800 - val_loss: 1.4090
Epoch 16/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 8s 131ms/step - accuracy: 0.9958 - loss: 0.0763 - val_accuracy: 0.9830 - val_loss: 1.3605
Epoch 17/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 8s 131ms/step - accuracy: 0.9930 - loss: 0.2647 - val_accuracy: 0.9810 - val_loss: 1.5229
Epoch 18/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 8s 133ms/step - accuracy: 0.9980 - loss: 0.0880 - val_accuracy: 0.9840 - val_loss: 1.4253
Epoch 19/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 136ms/step - accuracy: 0.9972 - loss: 0.1184 - val_accuracy: 0.9810 - val_loss: 1.6614
Epoch 20/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 139ms/step - accuracy: 0.9959 - loss: 0.0887 - val_accuracy: 0.9820 - val_loss: 1.5769
Epoch 21/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 142ms/step - accuracy: 0.9954 - loss: 0.0806 - val_accuracy: 0.9820 - val_loss: 1.4920
Epoch 22/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 144ms/step - accuracy: 0.9954 - loss: 0.1451 - val_accuracy: 0.9800 - val_loss: 1.4189
Epoch 23/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 149ms/step - accuracy: 0.9931 - loss: 0.1829 - val_accuracy: 0.9810 - val_loss: 1.5181
Epoch 24/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 10s 158ms/step - accuracy: 0.9940 - loss: 0.1612 - val_accuracy: 0.9850 - val_loss: 1.1487
Epoch 25/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 9s 148ms/step - accuracy: 0.9970 - loss: 0.0544 - val_accuracy: 0.9780 - val_loss: 1.5528
Epoch 26/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 10s 155ms/step - accuracy: 0.9942 - loss: 0.2046 - val_accuracy: 0.9820 - val_loss: 1.3084
Epoch 27/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 10s 159ms/step - accuracy: 0.9972 - loss: 0.0827 - val_accuracy: 0.9800 - val_loss: 1.4271
Epoch 28/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 10s 167ms/step - accuracy: 0.9946 - loss: 0.0846 - val_accuracy: 0.9840 - val_loss: 1.0937
Epoch 29/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 10s 167ms/step - accuracy: 0.9986 - loss: 0.0148 - val_accuracy: 0.9810 - val_loss: 1.1957
Epoch 30/30
63/63 ━━━━━━━━━━━━━━━━━━━━ 10s 163ms/step - accuracy: 0.9949 - loss: 0.1519 - val_accuracy: 0.9840 - val_loss: 1.1620
test_model = keras.models.load_model( "fine_tuning.keras")
test_loss, test_acc = test_model.evaluate(test_dataset)
print(f"Test accuracy: {test_acc:.3f}")
63/63 ━━━━━━━━━━━━━━━━━━━━ 5s 67ms/step - accuracy: 0.9787 - loss: 1.5189
Test accuracy: 0.980